最近一直在用 Rails 写 Web 项目, 在项目开发过程中, 一直遇到一个问题:
JavaScript 代码在重新刷新的时候工作正常
但是只要在浏览器中前进后退一下, JavaScript代码就会执行多次
而且跟页面来回切换的次数呈相关性
可以通过 Chrome 的调试工具来查看多次 XHR 请求:
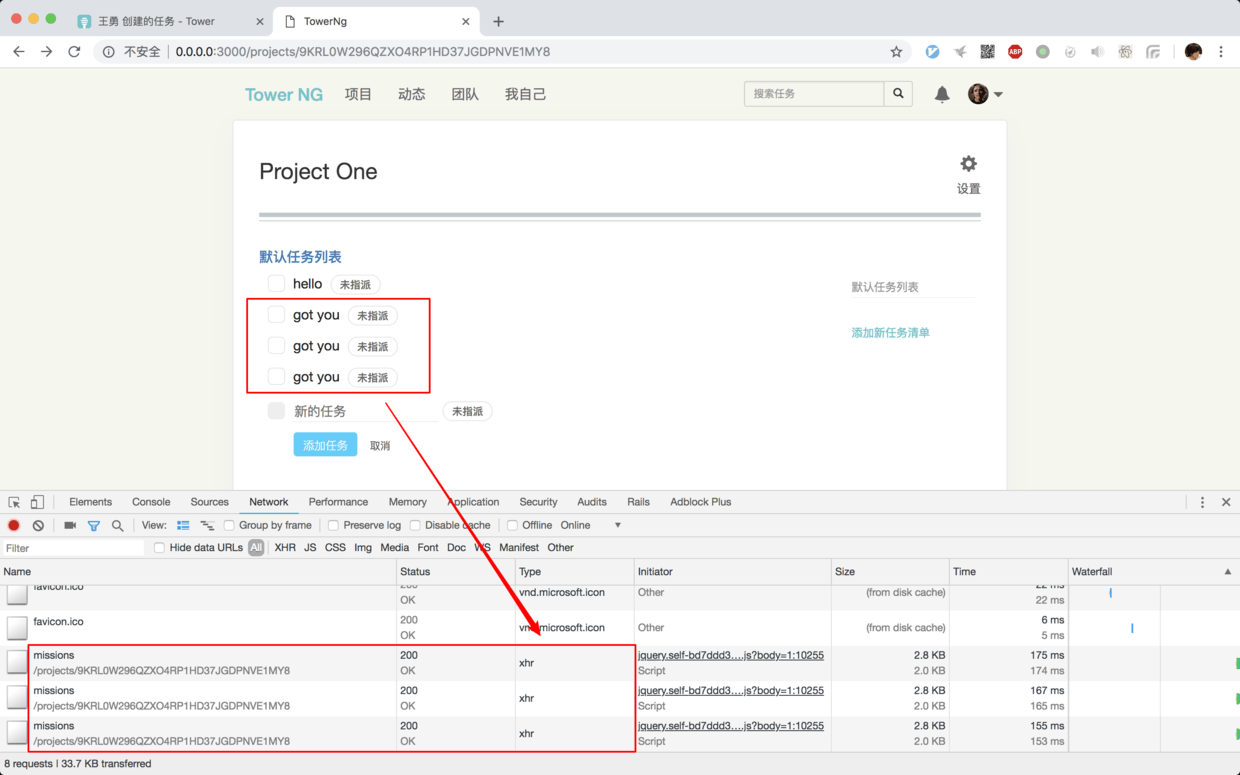
刚开始的时候, 没有特别在意, 因为一直在关注整个项目的架构设计和数据结构, 没有太在意这个小问题, 心里觉得可能是 Rails 哪里自己还没有彻底弄懂才导致的小问题.
直到昨天晚上开发完一个功能后, 发现 JS 代码居然重复执行了十次, 而且今天还要引入另外一个重要的功能, 从编程习惯上, 告诉自己是时候解决这个问题了, 否则以后搬着石头砸自己的脚…
早上的时候用 Google 搜索了相关的现象, 看了越来越多的 github issue 和 StackOverFlow 文章, 猜测问题估计出在 Turbolink 上, 但是究竟是哪里出了问题并不知道.
下午在医院等老婆的时候, 决定好好地看一下 Turbolink 相关的材料, 包括官网的手册, Turbolink 的历史, Turbolink 解决问题的目标以及 Turbolink 解决问题的思路.
看了一下午的材料, 虽然还是没有头绪, 但是脑袋里对 Turbolink 理解的更加深刻了.
Turbolinks 的历史和基本原理
- Rails 里的 Assets Pipeline 会把 JavaScript、StypeSheet 等资源都合并成单个文件, 以减少浏览器需要发起的请求数量, 以加速浏览器加载页面的时间
- Assets Pipeline 的这种原理导致单个文件本身比较大, 如果每次都是全页刷新, 对加载速度一定会有影响, 所以 DHH 引入 Turbolinks 来解决重复载入和解析资源文件的时间浪费
- 页面加载速度 = 下载资源速度 + 解析资源速度, Turbolinks 解决的主要是解析资源的速度, 当切换页面时, Turbolinks 会检查新页面 head 中 link 与 script 标签, 识别其中带有 data-turbolinks-track 的属性, 如果 src 发生变化, 就重新载入所有页面, 如果没有变化只是用新页面的 body 来替换老页面的 body 内容, 从而在绝大部分时间里避免每次重复解析和加载 head 中资源文件的时间(这个时间非常耗时)
Turbolinks 的缓存机制
Turbolinks 在每一次访问页面后, 都会缓存当前页面, 默认最多缓存 20 个. 缓存页面有两个用途:
- 使用浏览器后退, 前进时, 直接从缓存中取出对应的页面并渲染.
- 通过 a 元素点击时, Turbolinks 会率先从缓存中取出页面, 渲染出来, 然后再通过 XMLHttpRequest 取得服务器最新的页面, 再替换掉缓存页, 并渲染最新的页面.
在浏览器后退时, Turbolinks 使用的是 cloneNode(true) 来缓存页面, 这样将导致它替换页面时丢失掉所有的事件绑定, 它必须重新解析执行其中的 script 脚本才能让缓存页面正常工作.
Turbolinks 的处理流程
- 浏览器第一次加载, 或点击刷新: 这种情况保持与浏览器的加载顺序一致.
- 点击浏览器后退或前进: 直接调取缓存页面并显示, 不再拉取服务端数据.
- 点击页面的 a 元素: 先尝试拉取缓存, 如果有, 渲染缓存页面, 然后同时拉取服务端新页面并替换缓存; 如果没有, 则异步拉取服务端新页面, 缓存之并渲染新页面.
下面是网络朋友画的一张 Turbolinks 的处理流程图:
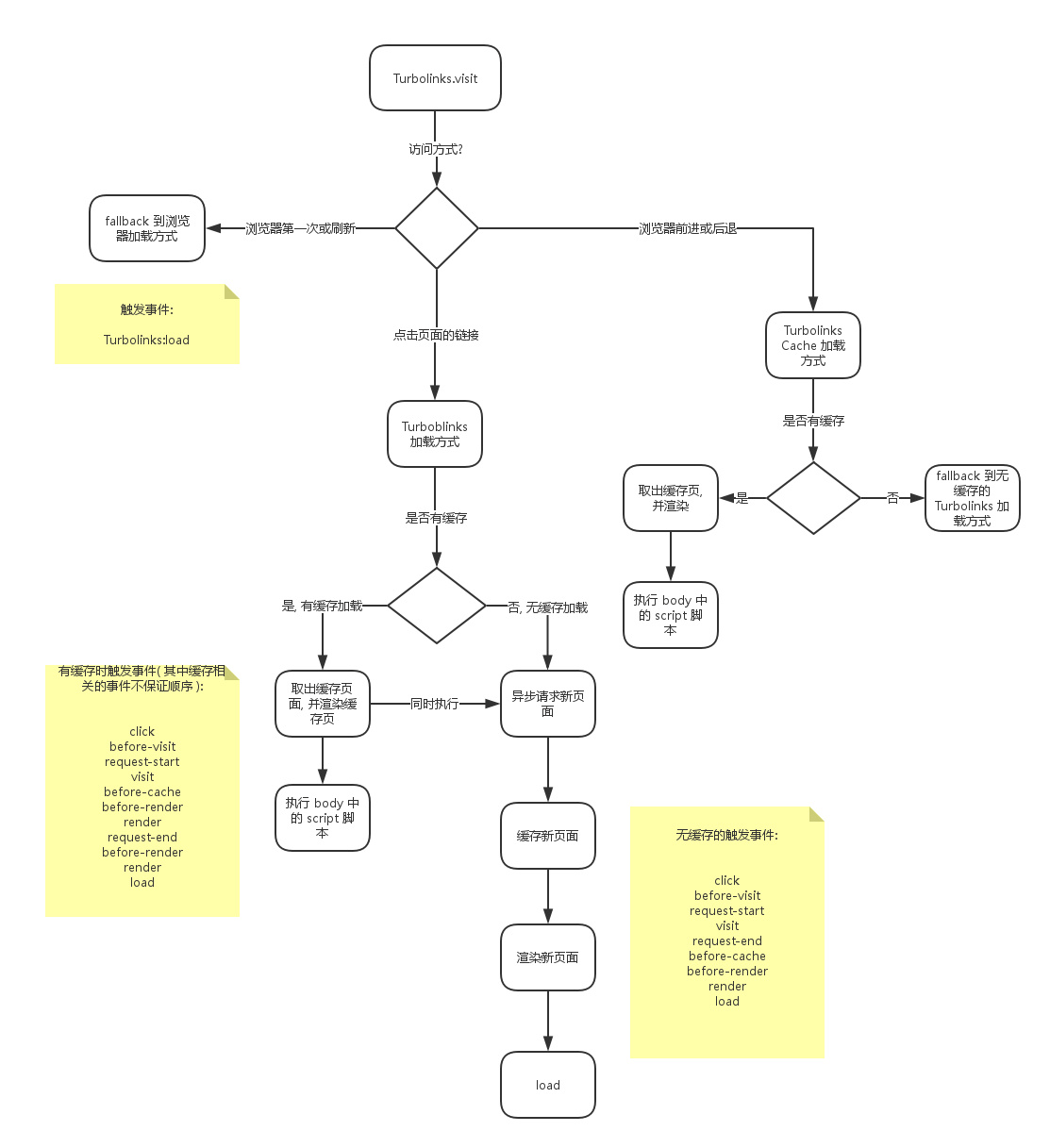
Turbolinks 解析页面的步骤分解
Chrome 解析页面步骤
- 下载 index.html
- 解析 head 标签中的 link 与 script 标签, 如果是带有 src 属性, 阻塞其他逻辑执行, 继续去下载对应的资源并执行. 如果没带, 则直接执行其中的代码逻辑.
- 渲染 body 标签的内容, 并解析执行 body 中的 script 标签.
- 全部执行完毕, 执行 DOMContentLoaded 事件绑定的逻辑.
第一次加载时网页执行跟上述是一致, 之后 Turbolinks 会绑定 Body 下所有的 a 元素的 click 事件, 切换页面时, Turbolinks 将会接管浏览器的页面加载过程, 采用以下方式:
Turbolinks 解析页面步骤
- 异步加载新页面的 index.html
- 解析 head 标签中的 link 与 script 标签, 识别其中带有 data-turbolinks-track 的属性, 如果 src 有变化( 可能性很小 ), 则重载所有页面. 如果没有变化, 则不进行任何操作.
- 解析 head 标签中新的 link 与 script 标签, 加载并执行.
- 用新页面的 body 替换老的 body 中的内容, 并执行其中的 script 脚本.
看完了网上大部分资料, 对于 Turbolinks 整体有一个大概的了解, 但是对于我文章最开始问题的原因还没有头绪, 加上 Turbolinks 的官方文档针对常见问题几乎没有 FAQ, 所以这时候就要运用逆向思维了:
- 手动在 head 中加入 script 代码, 不用 Turbolinks, 没有问题, 所以对比看, 问题出在 Turbolinks 的影响
- 为什么会多次加载 JavaScript 函数? 一定是被多次调用了
- 为什么 JavaScript 会被多次调用? 大胆猜测一下, Turbolinks 缓存的时候, 多次执行 script 部分的代码, 导致同一个 DOM element 被绑定了多次 JS callback, 所以点击一个 DOM element 执行了多次 JavaScript 函数, 一次是页面第一次加载时的 JS 代码, 更多次是 Turbolinks 缓存页面时多次执行 script 代码执行的
- 根据刚才整理的资料推理, 如果 CSS/JS 资源文件没变化, head 部分的资源解析过程只会做一次, 而我的 CSS/JS 文件一直没有发生变化, 所以不太可能是 head 部分代码的问题
- 如果 head 部分代码排除掉, 唯一的推理结论就是, Turbolinks 在缓存页面时, 因为页面发生变化, 替换了 body 的部分, 替换 body 部分以后还要执行 body 里的 script 脚本(请看上面 Turbolinks 解析页面步骤第 5 条)
逆向思考完毕后, 推理的假设是: 我的 body 模板中有 script 相关代码, 为了证明我的假设, 先查看一下渲染后的源代码:
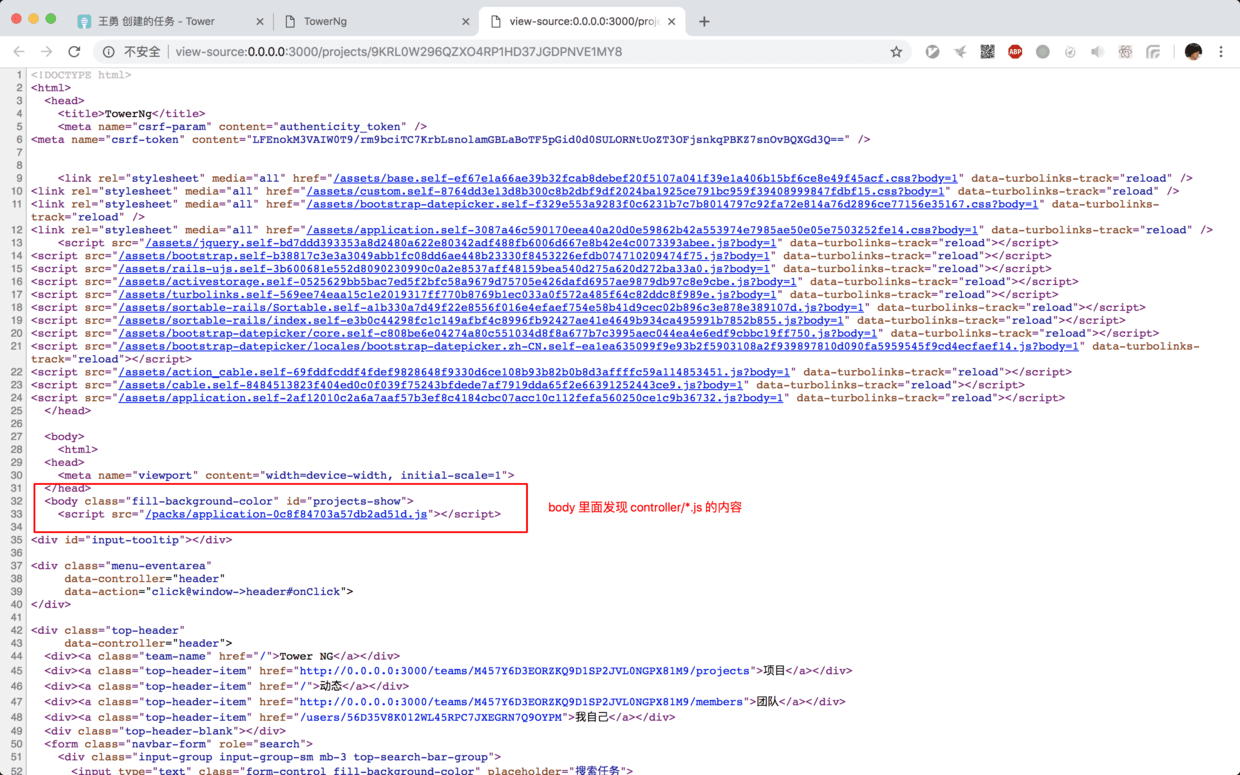
果然发现可疑的 script 代码, 上面的一大片 script 都是第三插件的代码, body 里的 script 点开, 发现都是我写的 Stimulusjs 相关的代码.
既然查看 HTML 源码证明了我的假设, 问题已经出在模板文件中, 用我的 color-rg 一番搜索 javascript 关键字以后, 发现在 _head.html.erb 模板文件中居然有这句:
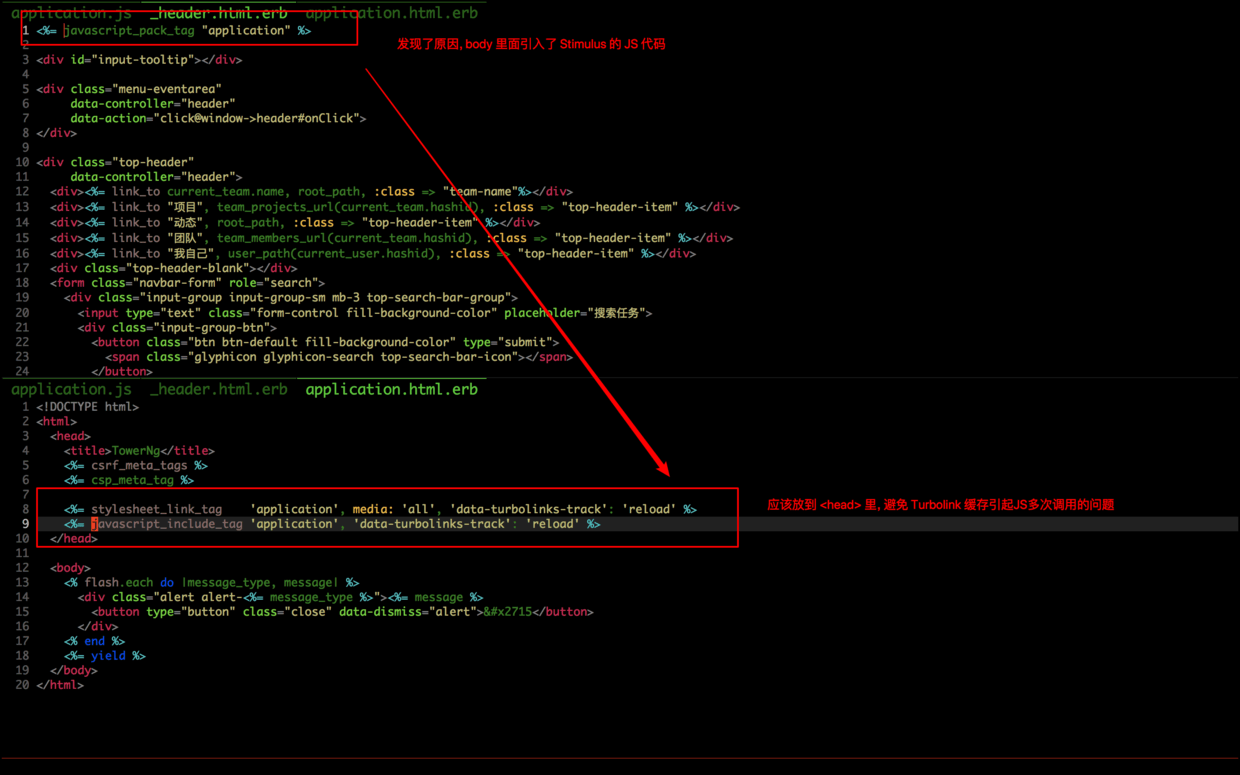
这不就是问题的原因吗? 太激动了
结合 Turbolinks 的缓存逻辑, 我其实只用把 javascript_pack_tag 的代码从 body 移动到 head 中, Turbolinks 缓存时 body 内容后就不会 script, 因为所有页面的 body 里面都没有 script 代码.
果然, 只移动一行代码以后, 问题完美解决:
最后
这就是我的学习方式, 当我们对一个难题久攻不克时, 不要着急去满世界找现成的答案, 即使答案不小心碰对了, 我们心中依然有困惑, 出来混的, 总有一天会还回去的.
当不知道答案时, 应该先放下问题, 多去看相关的资料, 相关的资料研究的越深, 潜意识就会在背后筹备线索, 当吃透的知识越多时, 即使你没法一眼看出问题,这些深厚的知识也会帮你编制一张无比严密的逻辑网帮助你逆向推理原因, 直到问题原因就蹦到你眼前, 迎刃而解.