怎么设计让多后端模糊搜索性能达到极致?
前天发布了 Snails 这个新型的模糊搜索框架。 Snails 的这个项目的主要目的是:
- 交互简单易用
- 5 分钟编写一个新的插件
- 搜索速度快
要让 Emacs 快, 我们首先要了解 Emacs 的优势和脾气, 这样我们从设计上才能让 Emacs 更快:
- 多线程不可行: Emacs 的多线程设计上, 每次只能运行一个线程上下文, 所以不能采用像 Gtk/Qt 那样通过子线程的思路来解决耗时搜索时不卡界面的方法, 因为一旦 Emacs 切换到耗时操作所在线程, 耗时操作放还是会卡主 Emacs。
- 多进程可行: 简单的搜索, 比如搜索打开的文件, 就放到 Emacs 进程中处理, 耗时的搜索需要放到子进程里面处理, 这样耗时搜索的时候就不会卡主 Emacs 了
- 避免子进程轰炸 Emacs: 子进程每更新一行结果不要去刷新 Emacs 的界面, 对用户的输入流畅性干扰很大, 在进程搜索完成以后再统一渲染结果, 所以后端 Shell 命令就要选择高效率的工具, 比如选 ripgrep 而不是 grep, 选 fd 而不是 find (Rust 大法好, 哈哈哈)
- 按键缝隙不要创建子进程: 一个人的输入间隔在 50ms ~ 200ms 之间, 因为子进程创建一次很昂贵, 所以在敲击键盘的时候就不要创建异步后端的子进程, 以节省系统资源, 这时候可以用
run-with-idle-timer函数做延迟处理, 当用户手指头一松开在发愣的时候才创建搜索子进程 - 尽快杀掉旧进程: 当用户输入很快时, 有一些子进程还在搜索旧的输入字符串, 可以在新的搜索进程开始之前尽快的杀掉那些还还没有结束的旧进程, 减少对系统资源的占用。
架构设计
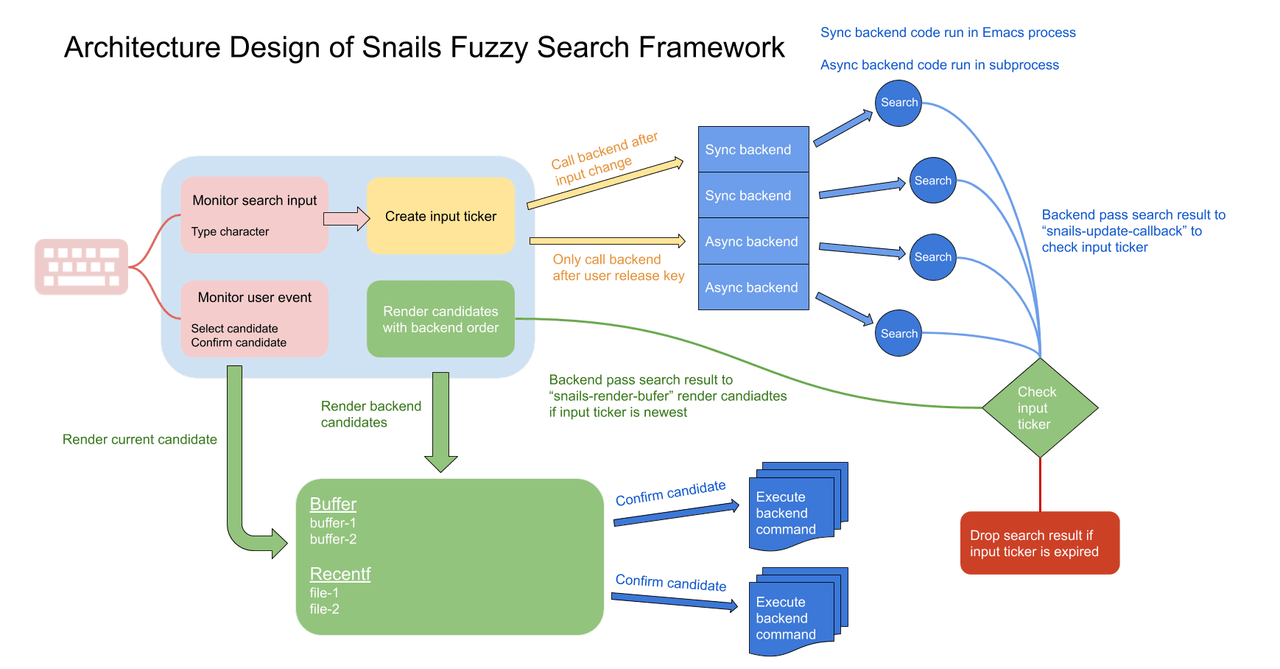
在想清楚设计思路以后, 代码实现就很简单了, 深入的思考和清晰的思路永远是架构设计的核心, 代码不过是架构设计的表现方式而已。
简单一句话来概括框架:
每次用户输入的时候框架分配一个新的 ticker ,
后端们自己去搜索, 得到结果的时候看看自己的 ticker 是不是最新的,
最新的就能用, 不是最新的就丢掉。
Snails 整体架构上分为框架部分和后端实现部分。
框架部分的职责:
- 监听用户输入, 生成新的 input ticker, 然后给所有后端分配搜索任务
- 检查后端的结果, 如果 input ticker 过期后抛弃后端搜索结果, 如果 input ticker 没有过期就染后端搜索结果
- 用户选择搜索结果后执行后端指定的命令
每次用户输入新的字符串后, 都会产生一个 input ticker 作为标记传给后端, 后端完成后需要带着标记来检查搜索结果是否过期(正在搜索的时候, 用户又进行了新的搜索)
同步后端是在用户输入变化的时候就启动, 异步后端是在用户手指头松开的一瞬间才启动。
这样既保证了简单搜索的及时响应, 又保障了耗时操作不会卡主 Emacs。
搜索后端的职责:
- 搜索和过滤字符串
- 解析出显示名和真实的搜索结果
- 用户确认后, 对搜索结果调用自定义命令
后端在实现时不用了解框架中处理细节, 只用做好搜索、 过滤和自定义命令就可以了。
一个完整的后端实现规模在 30~50 行, 一般在 5 分钟就可以写完整个后端插件的代码。
最后
欢迎来贡献新的插件, 一起来构建下一代模糊搜索框架。