EAF补强了 Emacs 的多媒体生态后,Emacs 离 VSCode 这种现代 IDE 最大的差距就是代码语法补全,VSCode 通过LSP协议实现了绝大多数编程语言的智能语法补全,而且操作性能极佳。
虽然 Emacs 也有 lsp-mode 和 eglot,但是受制于 Emacs 自身的单线程限制,如果 LSP Server 发送消息太多时,Emacs 会因为处理不过来而卡住,使用体验很不好。
五一节闭关研究了一下 LSP 协议,为 Emacs 实现了一个全新的 LSP 客户端: lsp-bridge。
lsp-bridge 通过 Python 多线程技术在 Emacs 和 LSP Server 之间建立一个缓冲桥梁,以实现完全不卡手的高性能 LSP 客户端。
下面,我们通过讲解 lsp-bridge 架构协议图来学习其设计思想和协议细节:
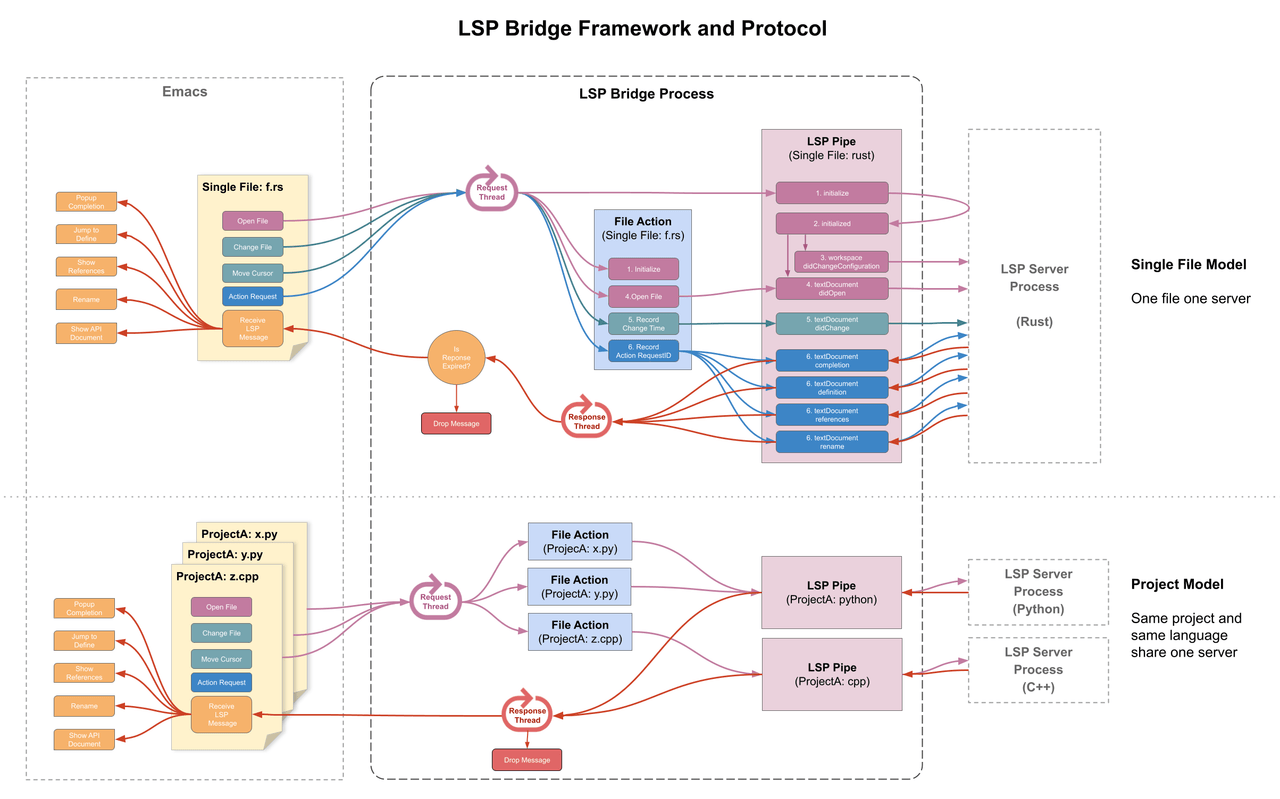
工程模型
首先上图分为两种模型,上面的部分是单文件模型,下面半部分是项目模型。
单文件模型主要是用户打开一个文件直接写代码,这个文件不属于任何 Git 项目,lsp-bridge 会根据文件的类型自动启动对应的 LSP 服务器来提供代码辅助服务,每个单文件对应一个 LSP 服务器,一般在脚本语言用单文件模型比较多,比如 Python,用户会经常创建一个临时文件来实验新想法 (是否是单文件可以通过命令 git rev-parse --is-inside-work-tree 来判断)。
项目模型主要是针对同一个项目的源代码提供代码辅助服务,lsp-bridge 会根据文件所属项目目录和文件类型来创建对应的 LSP 服务器,比如项目 A 中分别有三个文件 x.py、 y.py 和 z.cpp, lsp-bridge 会让 x.py 和 y.py 这两个文件共享一个 LSP Python 服务器, 给文件 z.cpp 启动一个 LSP C++服务器。这样当你在同一个项目中编辑不同的文件都会有 LSP 服务器来提供代码辅助服务,用户完全不用进行任何设置(项目根目录可以通过命令 git rev-parse --show-toplevel 来实现)。
无状态的线程模型
lsp-bridge 内部主要实现了两个线程循环,一个是 Request Thread,一个是 Response Thread。
Request Thread 主要用于接收 Emacs 发过来的请求,请求接收以后进入子线程循环中处理,不立即响应,以此来保证 Emacs 不会因为任何事件而等待。
Response Thread 主要处理 LSP Server 返回的消息,接收到消息后放入子线程中进行计算,计算有结果后再 push 处理结果给 Emacs,比如补全列表、重命名等信息。
lsp-bridge 每次向 LSP 发送消息时,都会生成一个唯一的 RequestID, 并缓存 RequestID 对应的文件路径、请求类型等信息,等 lsp-bridge 接收到服务器返回消息后,通过对比 RequestID 来判断返回的是什么类型的消息,整个消息流程都是完全无状态的线程模型,只通过 RequestID 来松散链接。
这样的设计好处是,Emacs 只用向 lsp-bridge 发送 LSP 请求,lsp-bridge 处理完 LSP 响应数据后向 Emacs 发送操作命令,双方完全不用等对方,从设计上就规避了 LSP Server 卡 Emacs 的可能性,即使 LSP Server 自身有 bug 卡住了,Emacs 也不会卡顿一下。
LSP 消息格式
在我们讲 LSP 协议之前,我们首先了解一下 LSP 的消息格式,不管 Server 还是 Client 都要用以下格式内容进行通讯:
Content-Length: 180\r\n
\r\n
{
"jsonrpc": "2.0",
"id": 1,
"method": "textDocument/didOpen",
"params": {
...
}
}
正常的解析过程是,第一行通过解析 Content-Length 字符串来提取消息的长度,接着读取一个空行扔掉,然后继续按照解析来的长度信息读取后续的消息内容,读取内容通过 json.load 来转换成 JSON 对象做进一步处理,样例代码如下:
first_line = self.process.stdout.readline().strip()
length = int(first_line[line.rfind(":") + 1:])
second_line = self.process.stdout.readline().strip()
message = self.process.stdout.readline(length).strip()
json.loads(message)
注意 LSP 消息的解析一定要严谨,错过一行消息或者解析错误都会导致实践中发生丢 LSP 消息的情况,解析 LSP 消息是后面所有章节的基础,这一章错误,后面的逻辑都会混乱, 建议用二进制模式读取管道内容,不要以文本的方式读取会导致读取的内容和 Content-Length 返回的长度不一致。
LSP 消息类型
LSP 客户端发送给服务器的消息一般有三种,分别是 Request、 Notification 和 Response, 这三种消息的格式细节区别是:
- Notification 消息不带 id 属性, Request 的 id 属性是 lsp-bridge 生成的,方便服务器返回的时候带上 id 用于识别消息类型, Response 的 id 属性一般是读取服务器返回消息的 id 后再发送回去,方便服务器根据 id 来处理客户端消息
- Request 消息包括 jsonrpc、 method、 params 和 id 四个字段, Notification 消息包括 jsonrpc、 method 和 params 三个字段, Response 消息包括 jsonrpc、 id 和 result 这三个字段
LSP 协议步骤
这一章的内容是最为关键的,一定要按照以下协议的顺序发送请求,否则 LSP Server 不会报错也不会有任何响应,当 LSP Server 没有任何响应时就很难进行调试。
要让 LSP 服务器正常工作的关键五个步骤依次是: 启动 -> initialize -> initialized -> workspace/didChangeConfiguration -> textDocument/didOpen:
1. 启动, 通过子进程的方式启动 lsp server, 然后通过子进程管道来和 lsp server 通讯:
以 Python 的 LSP 服务器 pyright 为例:
process = subprocess.Popen(["pyright-langserver", "--stdio"], bufsize=100000000, stdin=PIPE, stdout=PIPE, stderr=stderr)
process.stdin = io.TextIOWrapper(process.stdin, newline='', encoding="utf-8", write_through=True)
process.stdout = io.TextIOWrapper(process.stdout, newline='', encoding="utf-8")
- 第一行是启动 pyright 服务器,注意的坑是,必须通过
bufsize参数调大管道缓冲值大小, 避免管道堵塞后就无法接收服务器消息 - 第二行和第三行,主要通过
TextIOWrapper和newline参数来避免 Windows 平台的换行符导致无法解析 LSP 服务器返回消息的问题
2. 发送 initialize 请求:
先给服务器打个招呼,告诉服务器有 LSP 客户端在进行初始化操作。
send_to_request(
"initialize", {
"processId": os.getpid(),
"rootPath": root_path,
"clientInfo": {
"name": "emacs",
"version": "GNU Emacs 28.1 (build 1, x86_64-pc-linux-gnu, GTK+ Version 3.24.33, cairo version 1.17.6)\n of 2022-04-04"
},
"rootUri": project_path,
"capabilities": {},
"initializationOptions": {}
},
initialize_id)
这里面需要注意的几个地方:
- processId 是指当前进程的 pid, LSP 服务器会监听这个 pid, 如果父进程退出以后, LSP 服务器也会自动退出
- rootUri 的内容根据工程模型那一章讲解的,如果是单文件模型就传入单文件的文件路径,如果是工程模型就传入工程的根目录
- capabilities 和 initializationOptions 这两个参数, 除非 LSP 服务器明确需要配置才填写(比如 volar), 否则默认都设置成空, 填写错误参数会导致 LSP 服务器不发送任何响应消息回来,我第一次研究 LSP 协议就是这里乱填,一直接不到服务器返回消息,卡了好久
- initialize_id 用
abs(random.getrandbits(16))来生成一个随机的唯一 ID, 避免线程多了, RequestID 冲突
3. 发送 initialized 提醒:
接到 LSP 服务器对 initialize 请求的返回消息后, 发送 initialize 提醒消息给服务器,告诉服务器客户端已经确认准备好了,只有这个提醒发了以后 LSP 服务器才会响应后面的请求。
initialized 提醒内容最简单: send_to_notification("initialized", {})
4. 发送 workspace/didChangeConfiguration 提醒:
这一步主要是在 initialized 提醒消息发送后,马上对 LSP 服务器进行初始化配置,以 pyright 为例:
send_to_notification(
"workspace/didChangeConfiguration",
"settings": {
"analysis": {
"autoImportCompletions": true,
"typeshedPaths": [],
"stubPath": "",
"useLibraryCodeForTypes": true,
"diagnosticMode": "openFilesOnly",
"typeCheckingMode": "basic",
"logLevel": "verbose",
"autoSearchPaths": true,
"extraPaths": []
},
"pythonPath": "/usr/bin/python",
"venvPath": ""
})
这一步的关键是,每个 LSP 服务器的初始化配置都不一样,填不对配置, LSP 服务器也不理你,哈哈哈哈。
每个服务器对应的参数可以直接查看 lsp-bridge 的配置
5. 发送 textDocument/didOpen 打开文件提醒:
上面初始化和配置操作完成以后,需要马上调用 textDocument/didOpen 提醒消息,告诉 LSP 服务器打开文件的内容, 比如:
send_to_notification(
"textDocument/didOpen",
{
"textDocument": {
"uri": "file:///home/andy/foo.py"
"languageId": "python",
"version": 0,
"text": f.read()
}
})
一旦完成 textDocument/didOpen 消息发送后,后面就简单了,只用查看LSP 协议文档,向服务器发送消息,接到消息后解析 JSON 内容就可以快速开发 lsp-bridge 高级功能。
代码语法补全消息
textDocument/didOpen 消息后,其他消息都可以发送一个接收一个,代码语法补全消息要稍微复杂一点。
首先要监听 Emacs 的内容变化钩子 after-change-functions, Emacs 编辑文件后都要发送 textDocument/didChange 提醒消息给 LSP 服务器,让服务器可以实时保持文本内容和编辑器是一样的, 这样做的原因是, 如果编辑器不保存文件, LSP 服务器就不知道当前文件的最新内容,我们也不可能每次都发送全文件内容给服务器, 那样在处理大文件的时候会有性能问题, textDocument/didChange提醒消息一般长这个样子:
send_to_notification(
"textDocument/didChange",
{
"textDocument": {
"uri": "file:///home/andy/foo.py"
"version": version
},
"contentChanges": [
{
"range": {
"start": {
"line": start_row - 1,
"character": start_character
},
"end": {
"line": end_row - 1,
"character": end_character
}
},
"rangeLength": range_length,
"text": text
}]
})
textDocument/didChange 消息应该是 LSP 里面最复杂的一条消息, 需要根据 Emacs 编辑文本的变动同步给 LSP 服务器, 主要针对 start_row、 start_character、 end_row、 end_character、 range_length、 text 六个参数进行详细设计。
- start_row: 变动之前起始光标的行
- start_character: 变动之前起始光标的列
- end_row: 变动之前末尾光标的行
- end_character: 变动之前末尾光标的列
- range_length: 变动后字符串的长度
- text: 变动后的字符串
变动之前的状态需要通过 Emacs 的before-change-functions函数来跟踪,变动之后的状态需要通过 Emacs 的after-change-functions函数来跟踪。
当你正确的处理 textDocument/didChange 消息后,就可以发送 textDocument/completion 请求给服务器来获取当前光标处的语法补全信息:
if char in self.trigger_characters:
self.send_to_request(
"textDocument/completion",
{
"textDocument": {
"uri": "file:///home/andy/foo.py"
},
"position": {
"line": row - 1,
"character": column
},
"context": {
"triggerKind": 2,
"triggerCharacter": char
}
},
request_id)
else:
self.send_to_request(
"textDocument/completion",
{
"textDocument": {
"uri": "file:///home/andy/foo.py"
},
"position": {
"line": row - 1,
"character": column
},
"context": {
"triggerKind": 1
}
},
request_id)
这里需要注意的是,如果字符是补全触发字符,比如 ‘.’ ‘->’ 这些字符, triggerKind 的类型必须是 2, 并且需要同步发送触发补全的字符, 如果不是触发补全字符, triggerKind 类型必须是 1, 一般我们不发送 triggerKind 3, 避免一些服务器(比如 volar)不返回补全信息 。
触发字符在你发送 initialize 请求的时候, 服务器会返回对应的补全触发字符, 一般在 JSON 结构的这个位置 message["result"]["capabilities"]["completionProvider"]["triggerCharacters"]
诊断消息
LSP 3.16 的协议约定, LSP 服务器会一直发送诊断信息, 一般消息格式如下:
{
"jsonrpc": "2.0",
"method": "textDocument/publishDiagnostics",
"params": {
"uri": "file:///home/andy/test.py",
"version": 0,
"diagnostics": [
{
"range": {
"start": {
"line": 2,
"character": 7
},
"end": {
"line": 2,
"character": 8
}
},
"message": "Expected member name after \".\"",
"severity": 1,
"source": "Pyright"
},
{
"range": {
"start": {
"line": 4,
"character": 7
},
"end": {
"line": 4,
"character": 8
}
},
"message": "Expected member name after \".\"",
"severity": 1,
"source": "Pyright"
}
]
}
}
需要注意的是,因为服务器会一直发送诊断信息,信息量会非常大,为了提高编辑器编辑性能, 建议做一个缓存处理,当编辑器 idle 1 秒以后再拉取最新的诊断信息渲染到编辑器窗口内。
severity 是消息的类型:
severity == 1错误诊断severity == 2警告诊断severity == 3信息诊断severity == 4线索诊断
Code Action
LSP 服务器会针对现有代码的错误提供一些自动修复的功能, 常用于 Java 和 Rust 语言。
一般 Code Action 的消息如下:
{
"id": 46587,
"method": "textDocument/codeAction",
"params": {
"range": {
"start": {
"line": 3,
"character": 13
},
"end": {
"line": 3,
"character": 17
}
},
"context": {
"diagnostics": [
{
"range": {
"start": {
"line": 3,
"character": 13
},
"end": {
"line": 3,
"character": 17
}
},
"severity": 1,
"source": "rustc",
"message": "format argument must be a string literal",
"relatedInformation": [
{
"location": {
"uri": "file:///home/andy/world_hello/src/main.rs",
"range": {
"start": {
"line": 3,
"character": 13
},
"end": {
"line": 3,
"character": 13
}
}
},
"message": "you might be missing a string literal to format with: `\"{}\", `"
}
]
}
]
},
"textDocument": {
"uri": "file:///home/andy/world_hello/src/main.rs"
}
},
"jsonrpc": "2.0"
}
- range: 告诉 LSP 服务器需要修复的区域, 一般是光标处字符串或者选中区域范围
- context: 只有一个 diagnostics 列表, 注意诊断信息返回的时候需要保存一下当前文件所有的诊断信息, 在发送 Code Action 信息的时候, 需要根据
range的范围过滤出对应的诊断信息列表发给 LSP 服务器; context 还有一个only字段, 可以指定服务器只修复某些类型的错误, 3.16 协议支持这些类型的 Code Action: “quickfix”, “refactor”, “refactor.extract”, “refactor.inline”, “refactor.rewrite”, “source”, “source.organizeImports” - textDocument: 文件的 URI 链接
LSP 服务器返回内容一般如下:
{
"jsonrpc": "2.0",
"id": 46587,
"result": [
{
"title": "you might be missing a string literal to format with: `\"{}\", `",
"kind": "quickfix",
"edit": {
"changes": {
"file:///home/andy/world_hello/src/main.rs": [
{
"range": {
"start": {
"line": 3,
"character": 13
},
"end": {
"line": 3,
"character": 13
}
},
"newText": "\"{}\", "
}
]
}
},
"isPreferred": true
}
]
}
LSP 服务器会返回修复列表,你需要让用户选择一种修复方案后, 在 Client 根据 LSP 服务器的消息修改或替换特定的文件。
实践细节分享
候选词实现
每种语言的 LSP 服务器实现的完整度不一样,有些服务器会返回的多一点,有些服务器会返回的少一点,所以补全菜单的插入优先级应该按照 textEdit/newText->insertText->label 这三个等级来依次实现,注意当用 textEdit 来插入候选词时,需要根据 textEdit/rang/start 的信息作为替换起始位置。
侯选词的显示应该永远用 label 来显示, LSP 服务器有时候会返回 label 一样, 但是 annotation 不一样的候选词, 这种情况需要根据 annotation 的类型在 label 后面加一个空格, 避免补全前端过滤相同 label 的侯选词。
如果 textEdit/annotation 是 Snippet 类型, 还需要根据编辑器的插件实现 Snippet 展开。
LSP 服务器如果返回 additionalTextEdits 值, 还需要处理 additionalTextEdits, 一般这个信息是包含一些附加的操作,比如 auto-import 功能。
侯选词动态信息获取
默认发送 textDocumentation/completion 请求时, 候选词太多, LSP 服务器没法在短时间内计算所有候选词的 documentation 和additionalTextEdits 信息(一般是 auto-import 信息), 可以在用户在补全菜单上下选择时再向 LSP 服务器发送 completionItem/resolve 请求, 以动态的获取进一步的文档和补全信息, 这样可以兼顾补全的性能和信息的完备性。
注意, completionItem/resolve 的参数是一个 CompletionItem , 也就是 textDocumentation/completion 请求返回的 CompletionItem, 你需要在 LSP 客户端中完整缓存 CompletionItem 信息, 以方便在后续的 completionItem/resolve 请求中使用, 如果 CompletionItem 信息不全, LSP 服务器不会返回 documentation 和 additionalTextEdits 等附加信息, 只会原封不动的返回请求的数据, 这是一个比较细节的坑, 一定要注意。
--- Send (26155): completionItem/resolve
{
"id": 26155,
"method": "completionItem/resolve",
"params": {
"label": "expanduser",
"kind": 3,
"data": {
"workspacePath": "/home/andy/test.py",
"filePath": "/home/andy/test.py",
"position": {
"line": 2,
"character": 12
},
"symbolLabel": "expanduser"
},
"sortText": "09.9999.expanduser"
},
"jsonrpc": "2.0"
}
--- Recv response (26155): completionItem/resolve
{
"jsonrpc": "2.0",
"id": 26155,
"result": {
"label": "expanduser",
"kind": 3,
"data": {
"workspacePath": "/home/andy/test.py",
"filePath": "/home/andy/test.py",
"position": {
"line": 2,
"character": 12
},
"symbolLabel": "expanduser"
},
"sortText": "09.9999.expanduser",
"documentation": {
"kind": "plaintext",
"value": "expanduser(path: PathLike[AnyStr@expanduser]) -> AnyStr@expanduser\n\nexpanduser(path: AnyStr@expanduser) -> AnyStr@expanduser\n\nExpand ~ and ~user constructions. If user or $HOME is unknown,\ndo nothing."
}
}
}
Character 处理
Client 向服务器发送当前光标的位置的时候, 要注意使用 utf-16 编码来计算 Tab 和 Space 的情况, 这是 LSP 协议的细节差异, 虽然文本都是用 utf-8 来传输, 但是唯独 character 信息要用 utf-16 来处理, 要不没法正确处理文本有 emoji 字符时的列信息。
重命名处理
编辑器重命名文件以后需要通过发送 workspace/renameFiles 提醒消息, 来告诉 LSP 服务器, 主要用途是让语言服务器启动更新 import 路径。 需要注意的是,这个只是提醒服务器,但是你在实现中依然需要对旧的路径发送 closeFile 提醒,对新的路径要发送 openFile 提醒, 这样 LSP 服务器才会在重命名后继续响应编辑器发送的 LSP 消息。
安装和使用 lsp-bridge
lsp-bridge 安装很简单, 为了保持最新的内容, 请大家直接查看 lsp-bridge 的README
注意: 开发者需要打开 (setq lsp-bridge-enable-log t) 选项, 以实时查看服务器的返回消息 (用户不用打开这个选项,以提高性能)。
一起开发 lsp-bridge
lsp-bridge 发布的短短几天,已经有 15 位开发者加入我们的团队,贡献 16 种编程语言的语法补全代码,包括 Java、 C、 C++、 Python、 Golang、 Rust、 Ruby、 Haskell、 Elixir、 Dart、 SCala、TypeScript、 JavaScript、 OCaml、 Erlang、 LaTeX 等语言。
目前已完成的功能包括代码语法补全、定义跳转、引用查看和重命名, 欢迎加入我们开发更多的高级功能。
持续给 lsp-bridge 做贡献的理由是我们可以保证永远不卡 Emacs, 实现行云流水的编程体验, 哈哈哈哈。