Emacs GC 一直是卡顿 Emacs 的主要元凶。
今天花了一点时间研究了 Emacs GC 的源代码 emacs/src/alloc.c, 关键代码在 garbage_collect 这个函数。
核心流程:
- 阻止用户输入: GC 操作之前先调用
block_input函数阻止用户输入, 并把 GC 标志位gc_in_progress设置为 1 - 标记可达对象: 用
visit_static_gc_roots和各种mark_xx函数, 扫描 Emacs 的一些根对象(比如全局函数定义、 变量定义、 Buffer 列表等), 最后通过函数mark_object把这些对象标记为‘可达’ - 清理垃圾对象: 通过
gc_sweep函数按照对象的类型(string, cons, float, interval, symbol, buffer, vector 等)进行扫描, 查看没有被第二步标记的对象, 释放其内存 - 允许用户输入: 通过
unblock_input函数解除输入阻止, 把 GC 标志位gc_in_progress设置为 0, 完成垃圾回收
Emacs 这种全局扫描的垃圾对象的算法策略, 主要的问题是, 随着 Emacs 对象增多(主要是 LSP 或 overlay 场景下短时间生成大量对象)时, 第二步标记和第三步清理的耗时会随着对象数量急剧增加, 一旦这两个过程的耗时超过 30~100 毫秒, 就会产生 Emacser 遇到的卡手现象, 如果这个过程超过 2 秒以上, 就会导致用户极度烦躁甚至强制 kill。
因为 Emacs 本身是单线程程序, 所以我们没办法把 GC 过程放到后台线程去跑。
研究方向:
针对 GC 性能优化, 我自己想了几个研究方向:
- 随时中断 GC: 在
garbage_collect过程中插入大量detect_input_pending判断, 如果 GC 过程中检测到用户有输入事件发生, 立即中断 GC 过程, 避免 GC 导致 Emacs 无法响应用户操作 - 双进程模型: 需要进行 GC 时, 通过类似 pdumper 的技术, 把当前 Emacs 的内存保存到磁盘中(为了性能可以用内存文件), 然后再根据 dump 文件开一个后台 Emacs 进程, 通过后台 Emacs 进程慢慢分析需要清理的对象, 分析完成发送清理列表给第一个 Emacs 进程进行清理
- 分代回收: 根据对象的创建时间进行分代分析, 那些创建时间非常短的对象(一般是临时变量)优先分析, 那些创建时间比较长的对象延迟分析(一般是插件引入的全局函数或者变量), 降低每次全局垃圾对象分析的规模
这三种方式的优缺点分析:
- 第一种, 就是比较简单粗暴, 随时中断 GC 以保持用户操作响应, 用户频繁输入的时候 GC 基本没有机会运行, 用户暂停的时候 GC 可以尽情的运行, 为了避免标记和清除的过程也卡住用户, 可以在
mark_xx和gc_sweep函数里面继续插入大量detect_input_pending判断, 只要detect_input_pending插入细粒度越细, 理论上可以做到 GC 不卡用户; 缺点是随时中断 GC 需要做很多状态恢复和代码保护, 避免 Emacs 崩溃(今天晚上已经尝试了第一种方法, 因为时间不够, 各种崩溃, 哈哈哈哈) - 第二种, 就是第一个 Emacs 完全不做 GC 分析, 让第二个进程做 GC 分析, 要卡也卡第二个 Emacs, 这种方案的优点是 Emacs 开发者不用关心 GC 兼容性问题, 正常写代码逻辑就好了, 缺点是比较占用内存资源, 或者让一部分 Emacser 洁癖用户心理不舒服
- 第三种, 通过时间戳或者 let 表达式进行创建时间标注, 避免让 Emacs 对一些常驻对象(比如插件引入的函数定义和全局变量等)进行检查, 多分析临时对象, 提高 GC 效率, 缺点是, 要大量改造 Emacs GC 代码, 难度到没啥, 主要是测试工作量比较大
统计分析
garbage_collect
改了一下 GC 代码, 针对garbage_collect每个小函数都打了时间戳, 下面是一些日志(时间是微妙):
GC start
visit_static_gc_roots: 45366 microseconds
mark_pinned_objects: 0 microseconds
mark_pinned_symbols: 0 microseconds
mark_lread: 0 microseconds
mark_terminals: 2 microseconds
mark_kboards: 4 microseconds
mark_threads: 134 microseconds
mark_gui: 5 microseconds
compact_font_caches: 4 microseconds
mark_buffers: 2218 microseconds
mark_finalizer_list: 0 microseconds
mark_and_sweep_weak_table_contents: 42 microseconds
gc_sweep: 10620 microseconds
gc rest part: 3 microseconds
GC total: 58952 microseconds
从统计看, GC 里面的耗时主要是三个函数:
- visit_static_gc_roots: 扫描一遍所有 Lisp_Object, 耗时占用 70%
- gc_sweep: 释放无用的垃圾对象, 耗时占用 19%
- mark_buffers: 释放 Buffer 的垃圾对象, 耗时 3%
- 其他所有函数占用 8%
所以 GC 目前看, 优化最大潜力就是 visit_static_gc_roots 和 gc_sweep 这两个函数, 因为单位是微妙, 其他函数的消耗都可以忽略不计。
visit_static_gc_roots
visit_static_gc_roots: 31064 microseconds
GC_ROOT_BUFFER_LOCAL_DEFAULT: 21692 microseconds
GC_ROOT_BUFFER_LOCAL_NAME: 2 microseconds
GC_ROOT_C_SYMBOL: 10 microseconds
GC_ROOT_STATICPRO: 6840 microseconds
进一步分析 visit_static_gc_roots 函数里面, 其中
visit_buffer_root (visitor,
&buffer_defaults,
GC_ROOT_BUFFER_LOCAL_DEFAULT);
占用 visit_static_gc_roots 函数 70%的计算时间。
for (int i = 0; i < staticidx; i++)
visitor.visit (staticvec[i], GC_ROOT_STATICPRO, visitor.data);
占用 visit_static_gc_roots 函数 22%的计算时间。
GC 调用次数
在大型 Markdown 文档中测试删除行操作, 操作一次, 产生了 12 次 GC 回收调用, 这 12 次加载一起 (+ 35967 36885 36038 35876 35993 35642 38283 36760 36464 36201 36414 39017) 总共 439 毫秒, 也就是说, 删除操作光 GC 就占用了 0.43 秒, 造成了明显的卡顿。
从统计看, 当 GC 卡顿时:
- 访问静态 GC 根(visit_static_gc_roots)的时间大约在 29 至 31 毫秒之间。
- 标记缓冲区(mark_buffers)的时间在 0.3 至 0.6 毫秒之间波动。
- GC sweep 的时间在 6.7 至 8.7 毫秒之间波动。
- GC 总时间(GC total)在大约 37 至 39 毫秒之间波动。
- GC 间隔(GC INTERVAL)波动较大,从 80 毫秒到 300 毫秒不等。
也就是说, GC 调用非常频繁, 最短 80 毫秒就会启动一次, 最长 300 毫秒就会启动一次, 也就是一秒钟启动次数在 3~12 次左右, 在这个间隔内,每次 GC 的消耗时间都在 38 毫秒左右。
Valgrind
今天用 valgrind 做了一些性能分析, 性能分析方法:
1. 运行 valgrind, 通过 valgrind 找出性能瓶颈
valgrind --tool=callgrind --simulate-cache=yes --collect-jumps=yes emacs
--tool=callgrind:使用callgrind工具分析性能。--simulate-cache=yes:模拟缓存行为,以捕获缓存命中/未命中等信息。这将有助于了解缓存效率对性能的影响。--collect-jumps=yes:收集跳转指令信息。这将有助于了解代码的分支预测效果。
等待 valgrind 启动完(需要十几秒), 运行 Emacs 卡顿的命令, Ctrl + C 结束分析
2. 看性能分析报告
kcachegrind callgrind.out.PID
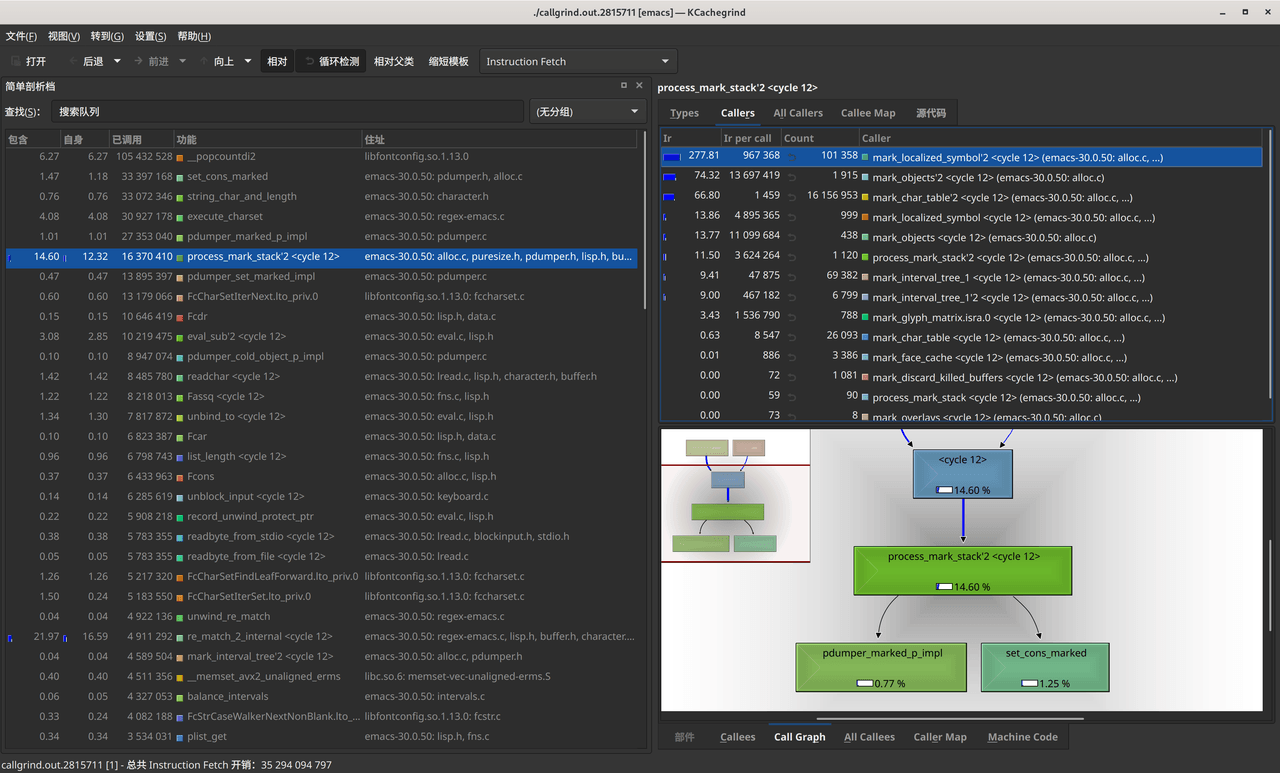
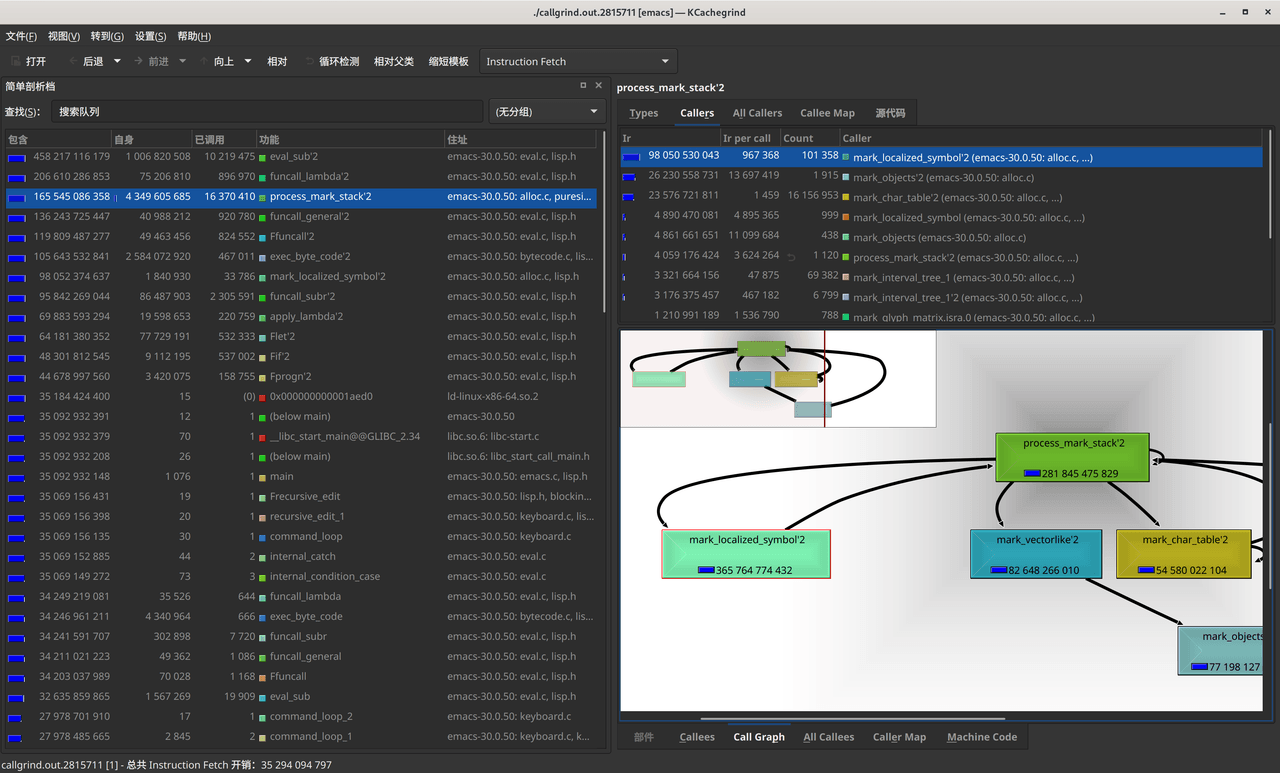
目前看 mark_localized_symbol 函数的性能占比非常高。
最后
以上是一些关于 Emacs GC 的研究, 因为时间关系, 很难在短时间内有进展, 前期只能先理理思路, 把思路分享出来抛砖引玉, 欢迎大家一起讨论贡献智慧。